在 Modern Android Development 系列中,涵盖了从编程语言到开发框架等各个环节, 随着 Kotlin 及 Jetpack 等新技术的出现 Android 开发方式发生了很大变化,以及推出的 Jetpack Compose 更是将这种变化推向了新阶段,Goolge 将这些新技术下的开发方式命名为 MAD ,以此区别于旧有的低效的开发方式。
本文将展开学习 MAD 的 Guide to app architecture 系列课程。
概念
MVX
MVX(MVC/MVP/MVVM):属于一种软件设计框架,将程序逻辑与用户界面分开,有助于组织代码并将程序分离为模块,从而使得开发更高效、模块更易于重用。
Android 中的 Clean Archtecture
Clean Archtecture 是一种软件开发方法,提供一种经济高效的流程来开发性能更好、更容易更改且依赖更少的高质量代码。
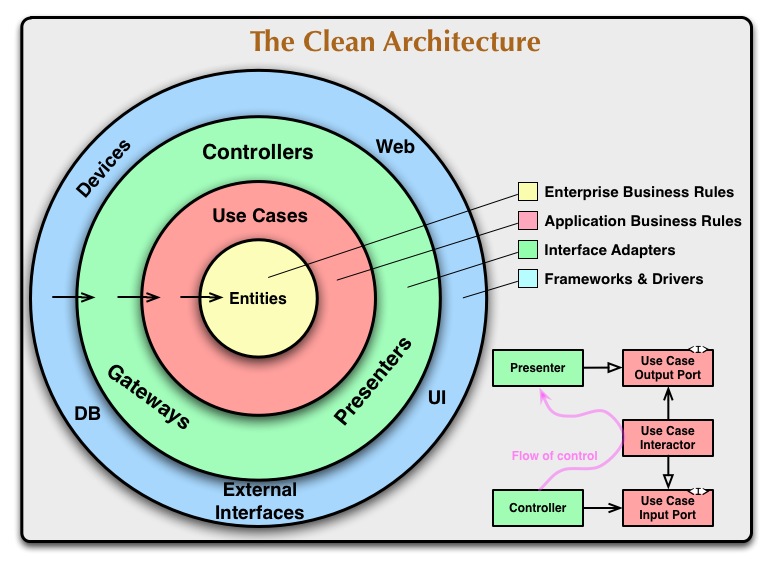
同心圆代表着软件的不同领域,根据抽象原则,最抽象的圆在中间,外圈是具体的实现细节;这套框架最重要的原则是依赖规则,规定着每个圈只能依赖最接近它的内圈,每个圈对外圈的事物没有知情权,这包括函数、类、变量或任何其他命名的软件实体。同时外圈中使用的数据格式不应该被内圆使用,规定外圈的任何东西都不能影响内圈。
Clean Archtecture 的优势
- 代码比标准 MVX 更易于测试
- 职责划分与隔离
- 用户友好的包结构
- …
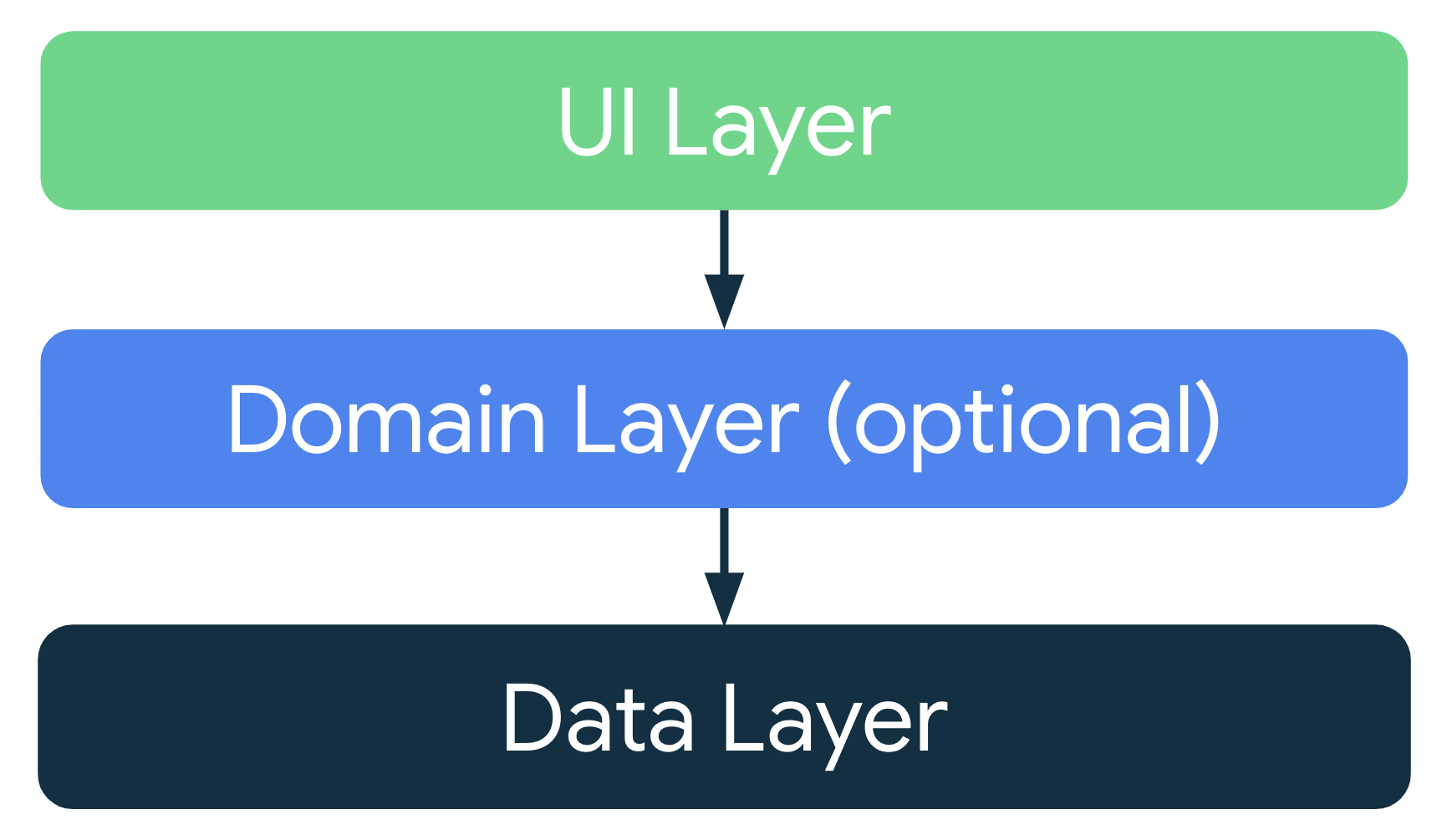
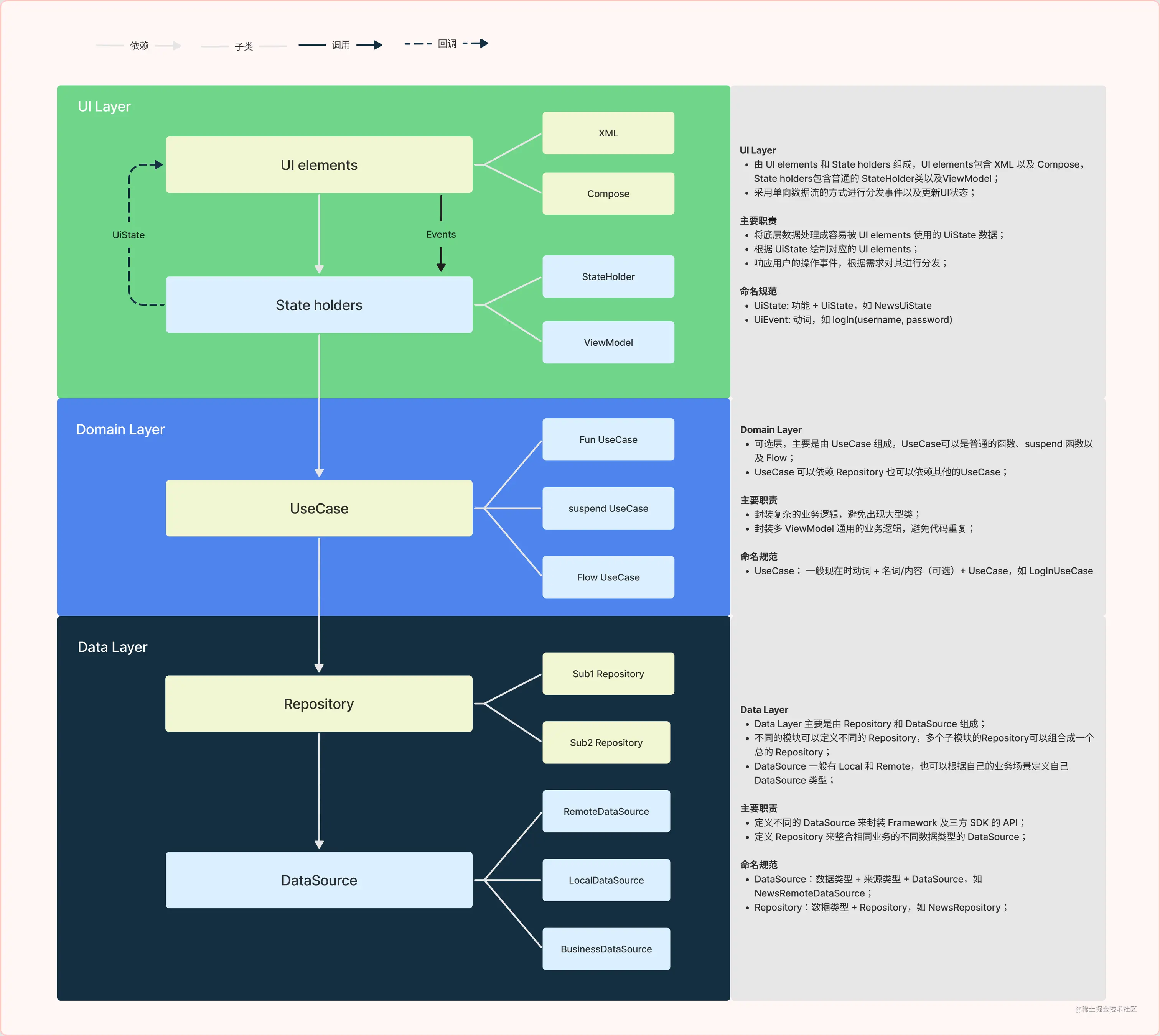
App Archtecture Layer Design(UI Layer-Domain Layer-Data Layer)
Android官方推荐的架构,更像是 Clean Archtecture 和 MVX(官方选用 MVVM)的结合。
架构指南
在 App 开发的过程中,一个合适的架构应该包含有以下优点:
- 功能要兼顾灵活的扩展或收缩
- 稳定性、健壮性
- 易于测试
所以一个合适的整体架构至少需要包含以下几大设计原则:
分离关注点
分离关注点是解决复杂问题的一种常见的解决方案,它是将一个计算机程序拆分为不同部分的设计原则。每一部分都有自己需要关注的焦点。从而达到将一个复杂问题拆解成多个简单问题的效果。
数据驱动页面
数据是项目的核心,也是状态的最终保存者。而视图,只不过是一种能够由数据延迟计算出来的最终结果而已,它本身不存储状态,View 只需要观察数据变化并做出响应即可。
KISS
KISS 同一问题的不同解决方案中,应该选择简单的那一个
SOLID
SOLD 面向对象变成的一些基本原则
应用架构推荐
App Arch Layer Design
UI Layer
界面层是作用在屏幕上显示应用数据。无论是因为用户交互还是外部输入(例如网络响应)导致数据发生变化时,界面都应更新以反应相应的变化。
界面从数据层获取的应用数据通常不同于所需要显示的信息格式,所以界面层要将应用数据变化转换为界面可以呈现的形式,然后将其显示出来,就呈现了如下流水线的模式:
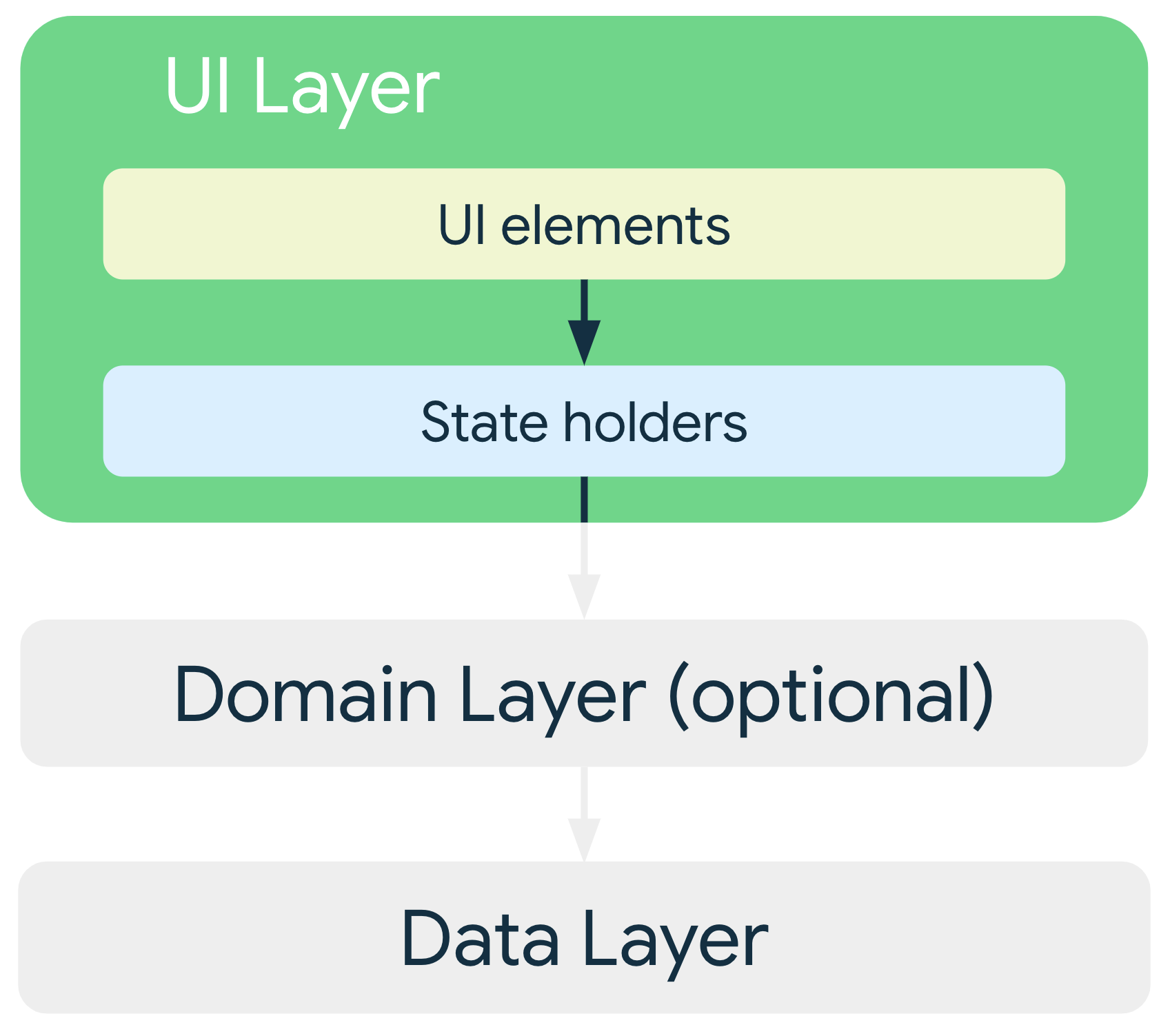
界面层架构
界面层主要由一下两部分组成:
- 在屏幕上呈现数据的界面元素(UI Element),可以使用 View 或 Jetpack Compose 来构建这些元素。
- 用于存储数据、向界面提供数据以及处理逻辑的状态容器(如 ViewModel)。
通过流程上的细分,界面层主要由以下几个部分组成:
- ViewModelContainer:View 的容器,作为 View 渲染的入口,一般指 Activity、Fragment
- UI Element:UI 元素,用来渲染界面的最小单元,View 或者 Jetpack Compose
- States holders:UI State 的持有者,负责提供界面状态,并且包含执行相应任务所必需的逻辑,一般指 ViewModel
- event:用户的交互事件,通常需要再产生、更新数据,代理给 ViewModel 处理
- UiState:UI 的状态数据,用来渲染 UI Element 的数据
定义界面状态
界面是界面状态的直观呈现,界面状态所做的任何更改都会立即反应再界面中。

界面状态的不可变性
推荐架构中界面状态的定义是不可变的,这样的好处是,不可变对象可保证即时提供应用的状态。这样界面便可专注于发挥单一作用:读取状态并相应地更新其界面元素。因此,切勿直接在界面中修改界面状态,除非界面本身是其数据的唯一可信源。违反这个原则会导致同一条信息有多个可信来源,从而导致数据不一致的BUG。
单向数据流(UDF)
作为提供和管理界面状态的方式。
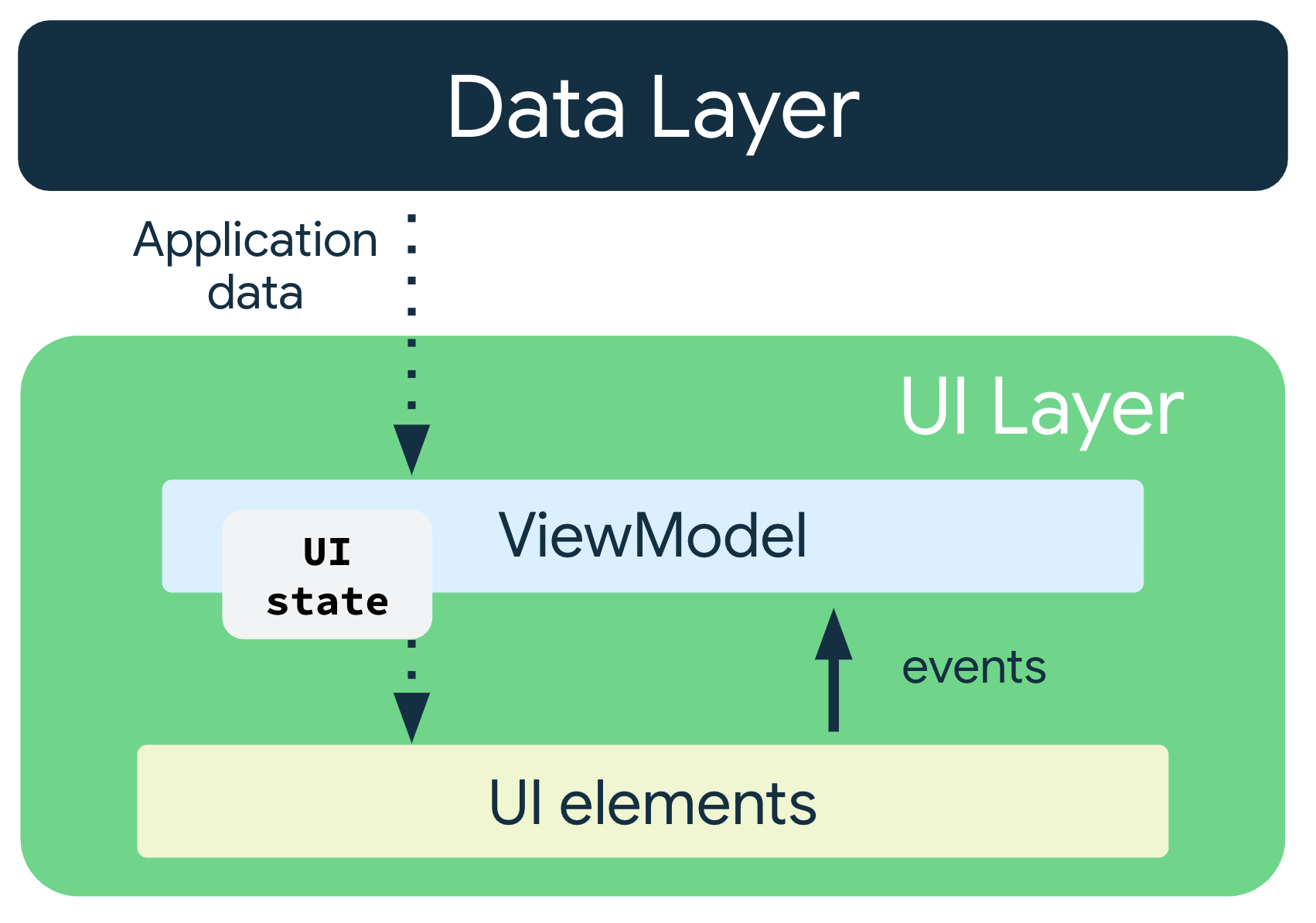
状态向下流动、事件向上流动的这种模式称为单向数据流 (UDF)。这种模式对应用架构的影响如下:
- ViewModel 会存储并公开界面要使用的界面状态。界面状态是经过 ViewModel 转换的应用数据
- 界面会向 ViewModel 发送用户事件通知
- ViewModel 处理用户操作并更新状态
- 更新后的状态将反馈给界面以进行呈现
- 系统会对导致状态变更的所有事件重复上述操作
为何使用 UDF ?
UDF 可为状态提供周期建模,它还可以将以下位置分离开来:状态变化来源位置、转换位置以及最终使用位置。这种分离可让界面只发挥其名称所表明的作用:通过观察状态变化来显示信息,并通过将这些变化传递给 ViewModel 来传递用户 intent。
UDF 有助于实现以下几个优点:
- 数据一致性:界面只有一个可信来源
- 可测试性:状态来源是独立的,以你独立于界面进行测试
- 可维护性:状态的变更遵循明确定义的模式,即状态更改是用户事件及其数据拉取来源共同作用的结果。
如何定义 UiState ?
UiState 通常会被定义为 data class ,除了包含UI绘制的元素,还会包含一些动作的处理,例如:isUserLoggedIn 根据这个字段处理页面跳转相关逻辑。在定义 UiState 的同时,需要考虑 UI 到底需要展示、处理哪些信息,也有一些原则需要遵守:
-
不可变性 状态字段要定义为常量而非变量,这样可以杜绝数据在传递过程被其他逻辑对其产生修改
-
使用统一的命名 功能 + UiState
-
UiState 应处理彼此相关的状态
data class NewsUiState( val isSignedIn: Boolean = false, val isPremium: Boolean = false, val newsItems: List<NewsItemUiState> = listOf() ) val NewsUiState.canBookmarkNews: Boolean get() = isSignedIn && isPremium -
合理使用单数据流和多个数据流
UI Events
在定义 UI Events 时需区分UI事件和用户事件,UI事件在 UI Elements 中处理而无需进一步分发,用户事件需要分发给对应的 State Holders。
Domain Layer
领域层,也称网域层,是位于界面层和数据层之间的可选层。Domain Layer 主要由不同的 UseCase 组成,其依赖关系如下:
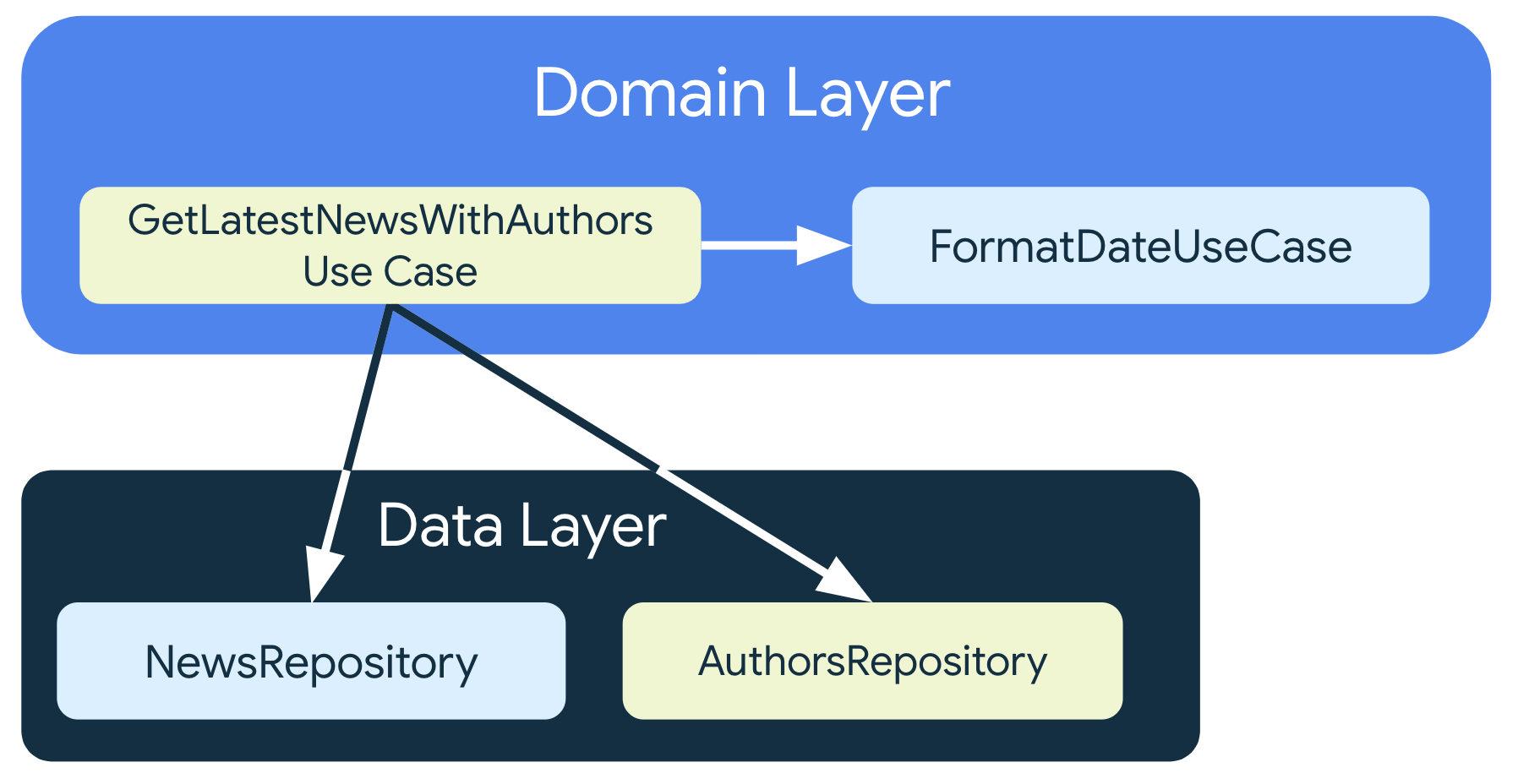
领域层负责封装复杂的业务逻辑,或者由多个 ViewModel 重复使用的简单业务逻辑。并非所有应用都有这类需求,所以应仅在需要时使用,例如处理复杂逻辑或支持可重用性。又或者,由于某 ViewModel 业务逻辑涉及多个 Repositories 并且可能会变得很复杂,因此可以创建 UseCase 类,将逻辑从 ViewModel 中提取出来并提高其可读性。
Domain Layer 的优势
- 避免代码重复
- 改善使用领域层类的可读性
- 改善应用的可测试性
- 更好的划分职责,避免出现大型类
UseCase 用例类
UseCase 是组成 Domain Layer 的具体执行类。用例类通常依赖于 Repositories 类,并且它们在界面层的通信方式与 Repositories 的通信方式相同(Java回调、Kotlin协程)。
为了使用例类保持简单轻量化,每个用例都应仅负责单个功能,且不应包含可变数据。(可变数据应在界面层或数据层中 处理)
某些情况下,用例类中可能存在的逻辑可以成为 Util 类中静态方法的一部分,不过,不建议采用后者,因为 Util 类通常很难找,而且其功能也很难发现。此外,用例还可以共享通用功能(例如积累中的线程处理和错误处理)。
如何定义 UseCase?
在 Kotlin中,可以通过使用 operator 修饰符定义 invoke() 函数,将用例类实例作为函数进行调用。
class FormatDateUseCase(userRepository: UserRepository) {
// 1、operator + invoke 来提供统一函数入口
// 2、传参及返回值可以自由定义
operator fun invoke(date: Date): String {
return userRepository.format(date)
}
}
生命周期
用例类没有自己的生命周期,而是受限于使用它们的类。由于用例类不应包含可变数据,因此每次将用例类作为依赖项传递时,都应该创建一个新实例。
线程处理
来自领域层的用例类应具有主线程安全性,如果用例类执行长期运行的阻塞操作,那么它们负责将改逻辑移至合适当的线程。
class MyUseCase(
private val defaultDispatcher: CoroutineDispatcher = Dispatcher.Defalut
) {
suspend operator fun invoke(...) = withContext(defalutDispatcher) {
// Long-running blocking operations happen on a background thread.
}
}
Data Layer
数据层包含应用数据和业务逻辑。业务逻辑决定应用的价值,它由现实世界的业务规则组成,这些规则决定着应用数据的创建、存储和更改方式。
这种关注点分离使得数据层可用于多个屏幕、在应用的不同部分之间共享信息,以及在界面以外复制业务逻辑以进行单元测试。
数据层由多个存储库组成,其中每个存储库都可以包含零到多个数据源。您应该为应用中处理的每种不同类型的数据分别创建一个存储库类。
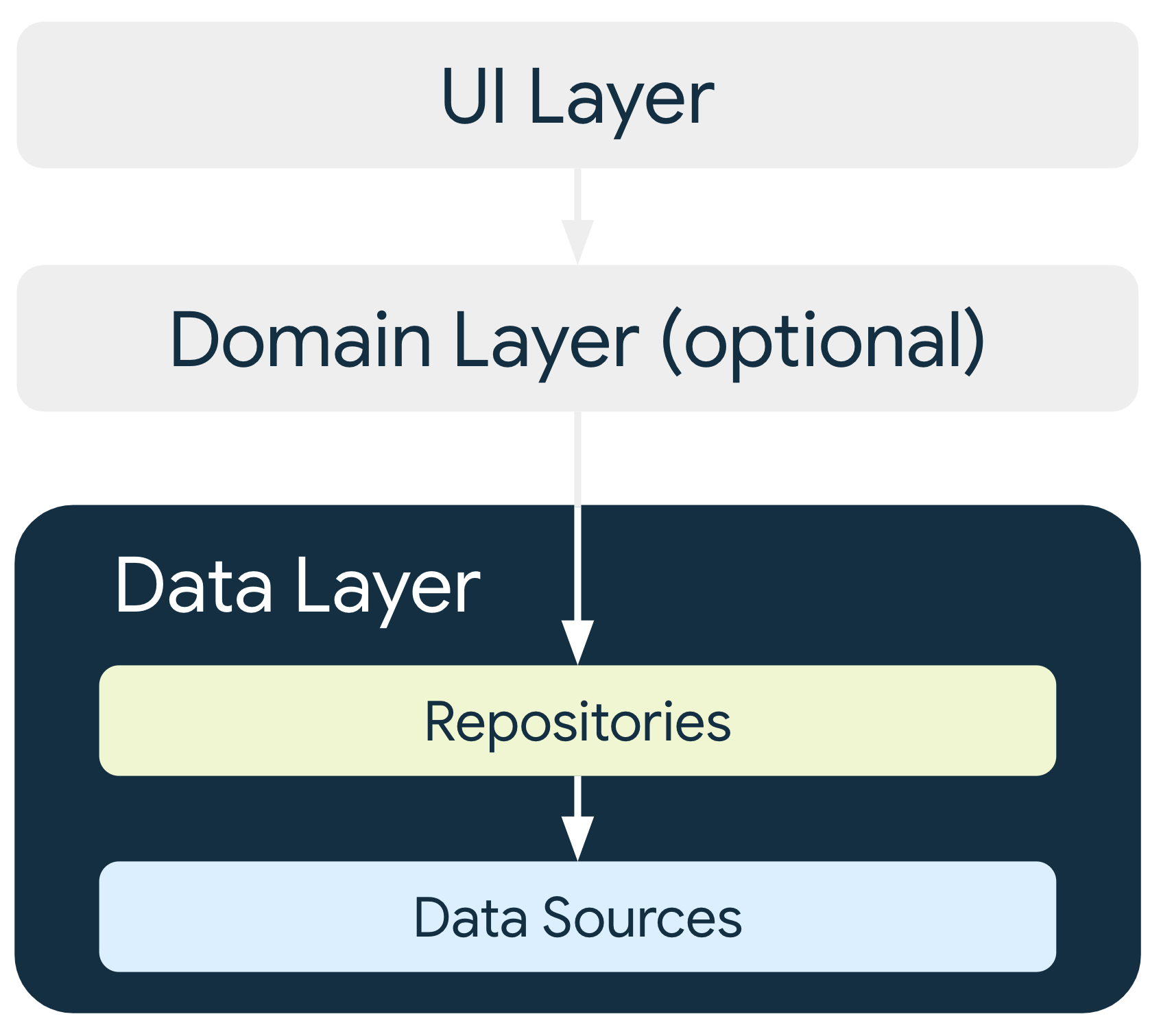
Repositories
Repositories 类主要负责以下任务:
- 向应用的其余部分公开数据
- 集中处理数据变化
- 解决多个数据源之间的冲突
- 对应用其余部分的数据源进行抽象化处理
- 包含业务逻辑
Data Source
Data Source 类是应用与负责数据操作的系统之间的桥梁。相应的数据源可以是 File、Netwrok、DataBase等。
命名规则:数据类型 + 来源类型 + DataSource 例如:NewsRemoteDataSource
多层 Repositories
在某些涉及更复杂业务要求的情况下,存储库可能需要依赖于其他存储库。这可能是因为所涉及的数据是来自多个数据源的数据聚合,或者是因为相应职责需要封装在其他存储库类中。
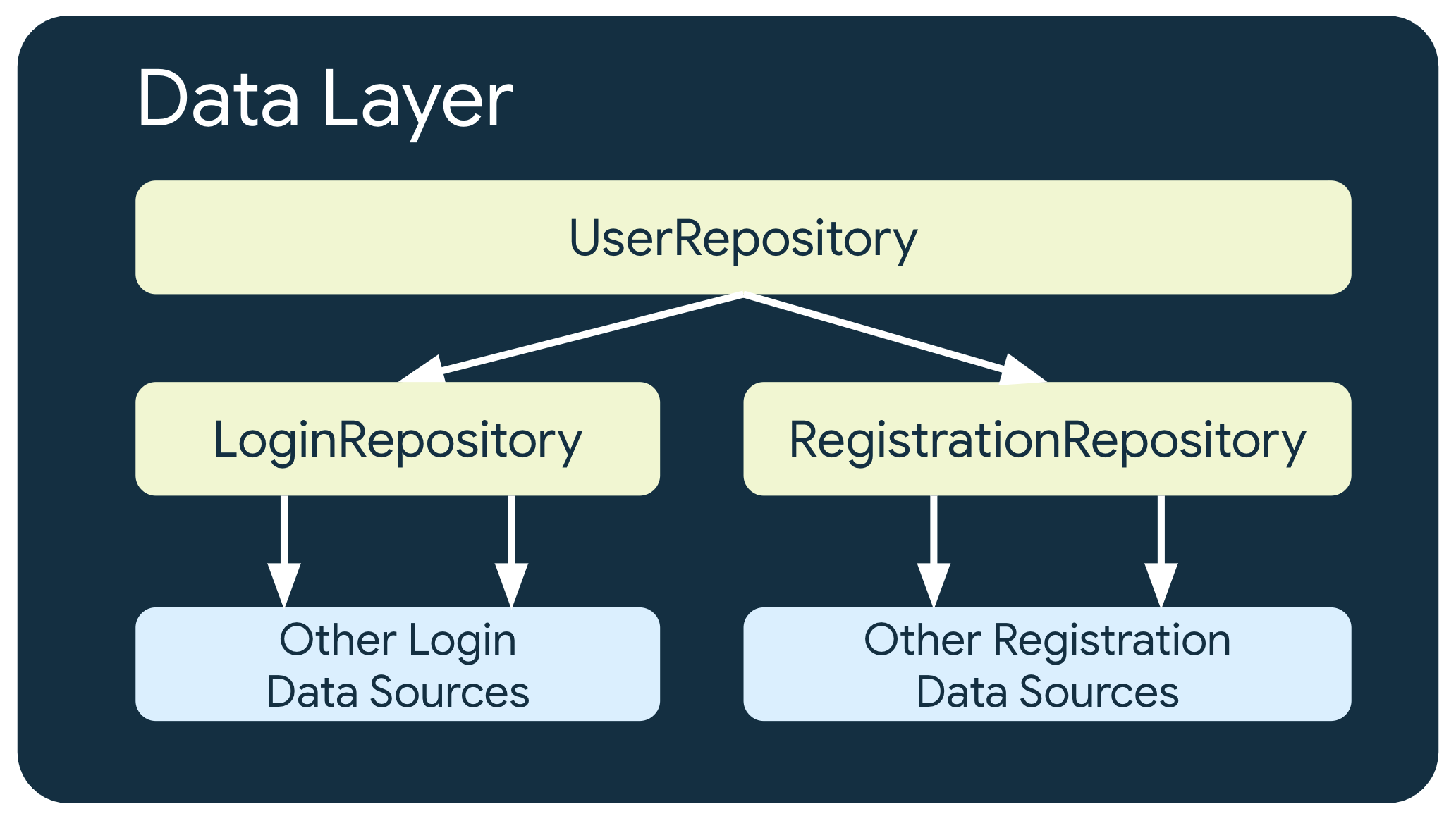
可信来源
为了提供离线优先支持,建议使用本地数据源(例如数据库)作为可信来源。
数据操作类型
数据层可以处理的操作类型会因操作的重要程度而异:
- 面向界面的操作 面向界面的操作仅在用户位于特定屏幕上时才相关,当用户离开相应屏幕时便会被取消。例如,显示从数据库获取的部分数据。 面向界面的操作通常由界面层触发,并且遵循调用方的生命周期,例如 ViewModel 的生命周期。
- 面向应用的操作
只要应用处于打开状态,面向应用的操作就一直相关。如果应用关闭或进程终止,这些操作将会被取消。例如,缓存网络请求结果,以便在以后需要时使用。
这些操作通常遵循
Application类或数据层的生命周期。 - 面向业务的操作 面向业务的操作无法取消。它们应该会在进程终止后继续执行。例如,完成上传用户想要发布到其个人资料的照片。 对于面向业务的操作,建议使用 WorkManager。
总结
参考文献: